本記事では「OECD FRAMEWORK FOR THE CLASSIFICATION OF AI SYSTEMS」について原文を翻訳・意訳しながら日本語でまとめ、同フレームワークの理解を深めることを目的としています。原文はこちらからアクセスをお願いします。
一言でわかりやすく説明するとすると、「AIシステムの特性と相互作用を整理するためのフレームワーク」となると思います。AIシステムを表現する観点として5つのディメンジョンが定義され、それぞれ異なるAIシステムを共通のフレームワークを用いて整理できます。原文にも政策立案者、規制当局、議員などが人々が特定のプロジェクトやコンテキストに合わせて AI システムを特徴付けるための使いやすいフレームワークとして開発されたとあります。本フレームワークは次のベースラインを提供します。
- AI についての共通理解を促進する: 最も重要な AI システムの機能を特定し、政府やその他の企業が特定の AI アプリケーションに合わせて政策を調整できるようにし、より主観的な基準 (幸福への影響など) を評価するための指標の特定または開発を支援する
- レジストリまたはインベントリに情報を提供する: アルゴリズムまたは自動意思決定システムのインベントリまたはレジストリにおけるシステムとその基本特性を説明するのに役立つ
- セクター固有のフレームワークのサポート: 医療や金融などのセクターにおける、より詳細なアプリケーションまたはドメイン固有の基礎を提供する
- リスク評価のサポート: リスク回避と軽減に役立つリスク評価フレームワークを開発し、インシデント報告における世界的な一貫性と相互運用性を促進する AI インシデントに関する報告のための共通フレームワークを開発するための関連作業の基礎を提供する
- リスク管理のサポート: コーポレート ガバナンスに関するものも含め、AI システムのライフサイクルに沿った緩和、コンプライアンス、施行に関する関連作業の情報提供を支援する
AIシステムの特性と相互作用を構成する主要なディメンジョン
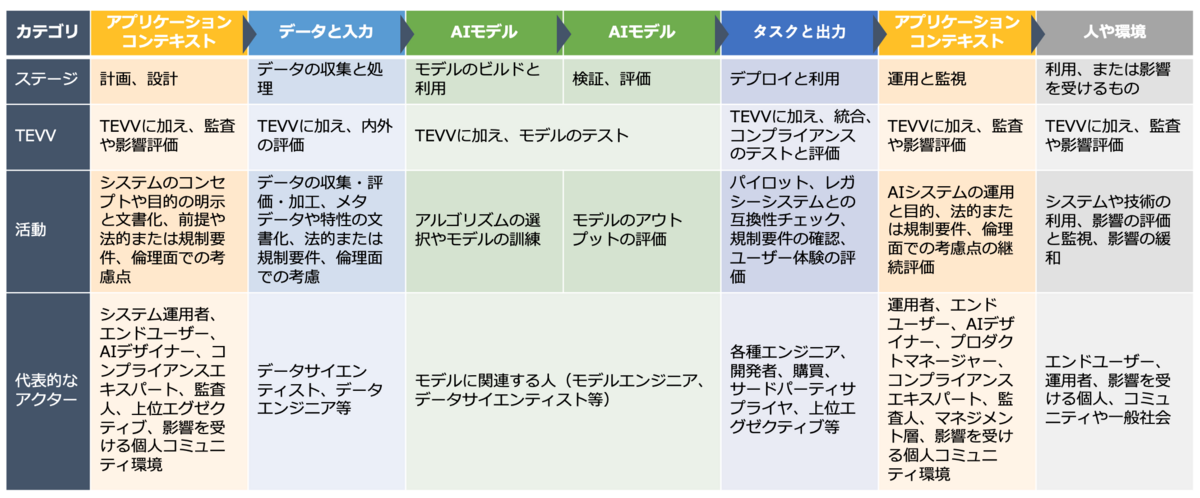
本フレームワークは、人と地球、経済的コンテキスト、データと入力、AIモデル、タスクと出力の5つディメンジョンに沿ってAIシステムとアプリケーションを分類します。 それぞれには、AIシステムの考慮事項の評価に関連する独自のプロパティと属性、またはサブディメンションがあります。
人と地球: 人と地球に利益をもたらす、人間中心で信頼できるAIを促進するAI システムの可能性を考慮しています。 それぞれのコンテキストにおいて、AIシステムと相互作用する、またはAIシステムの影響を受ける個人およびグループを識別します。 主な特徴には、ユーザーと影響を受ける利害関係者だけでなく、アプリケーションのオプション性と、それが人権、環境、幸福、社会、仕事の世界にどのような影響を与えるかが含まれます。
経済的コンテキスト: AIシステムが実装される経済的および分野別の環境とAIシステムが開発される組織の種類と機能領域について説明します。 特徴には、システムが導入されているセクター (ヘルスケア、金融、製造など)、そのビジネス機能およびモデル、性質、そ入、影響、規模、および技術的成熟度が含まれます。
データと入力: AIモデルが環境の表現を構築するために使用するデータや入力について説明します。 特性には、データと入力の出どころ、データの収集方法、データの構造と形式、データのプロパティが含まれます。 データと入力の特性は、AI システムのトレーニングに使用されるデータ「in the lab」と生産で使用されるデータ「in the field」に関係します。
AI モデル: AIシステムの全てまたは外部環境の一部を計算的に表現したもので、たとえば、その環境で行われるプロセス、オブジェクト、アイデア、人々、相互作用が含まれます。 主な特性には、技術的な種類、モデルの構築方法 (専門知識、機械学習、またはその両方を使用)、モデルの使用方法 (どのような目的で、どのようなパフォーマンス測定値を使用するか) が含まれます。
タスクと出力: システムが実行するタスク、例えばパーソナライゼーション、認識、予測、または目標主導型の最適化、その出力、そしてその結果として全体的なコンテキストに影響を与えるアクションを指します。このディメンジョンの特性には、システム タスク、行動の自主性、自動運転車のようにタスクとアクションを組み合わせるシステム、コンピュータビジョンなどのコアアプリケーション領域、および評価方法が含まれます。
フレームワークの各ディメンジョンには、さまざまな AI システムに関連する考慮事項の属性、またはサブディメンジョンがあります。 ステークホルダーには、AIシステムに関係する人、またはAIシステムの影響を受ける人が含まれます。 AIアクターは、AIシステムのライフサイクル全体を通じて積極的な役割を果たすステークホルダーであり、各側面に応じて異なります。

AIシステムの各分類ディメンジョン毎の性質と、キーとなるAIアクターが整理されたものが以下のフローとなります。
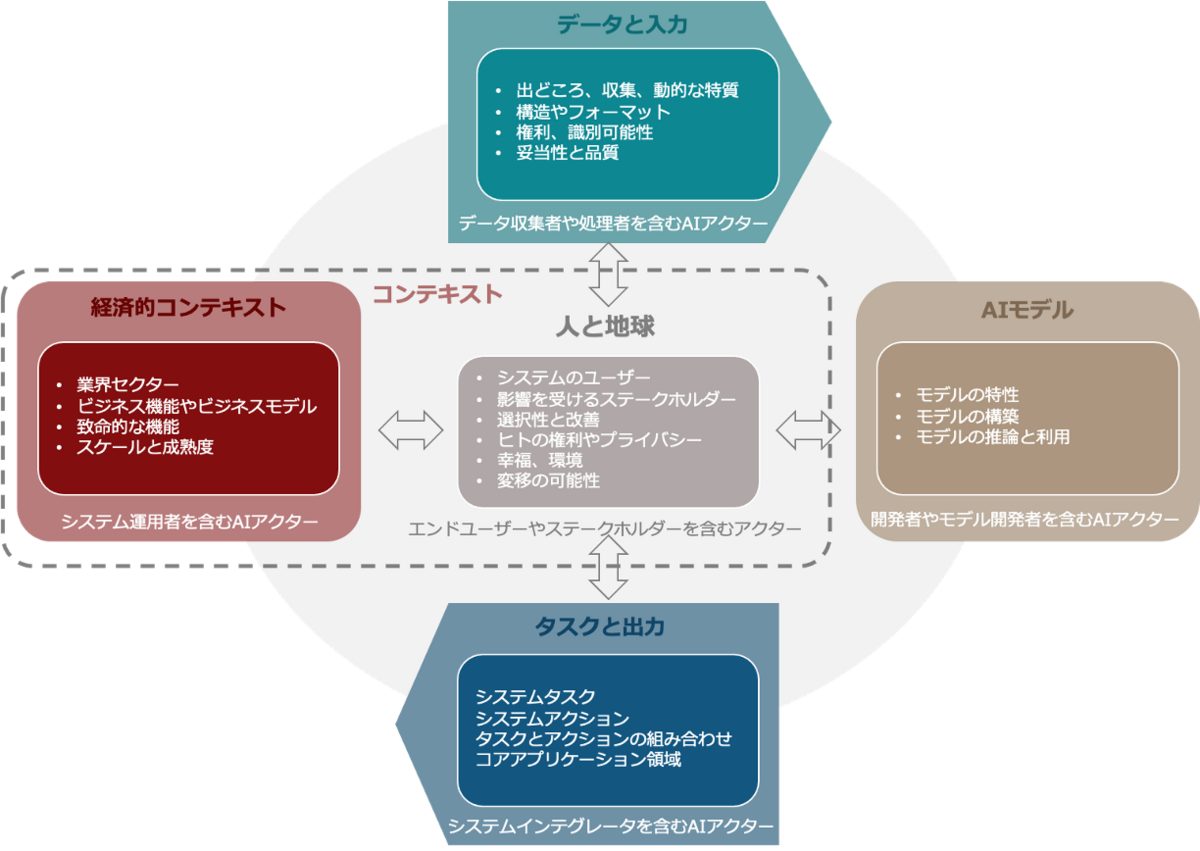
- AIの「in the lab」とは、導入前のAIシステムの構想と開発を指します。 これは、フレームワークのデータと入力 (データの修飾など)、AIモデル (初期モデルのトレーニングなど)、およびタスクと出力のディメンジョン (パーソナライゼーション タスクなど) に適用できます。 これは、事前のリスク管理アプローチと要件に特に関連します。
- 「in the field」AIとは、導入後のAIシステムの使用と進化を指し、特に事後のリスク管理アプローチと要件に関連します。 これは、人々と地球、経済的コンテキストを含むすべての次元に適用できます。 さらに、「in the field」AIシステムは、特に導入範囲の広さ、技術の成熟度、ユーザーと機能に関して、時間の経過とともに多くの大幅な変化を起こす可能性があることを強調することが重要です。 たとえば、これはモデル構築に利用できるようになった改良されたデータセットや異なるデータセットによって発生する可能性があります。
AIシステムのライフサイクルは、システムの主要な技術的特性を理解するための補完的な構造として機能します。 ライフサイクルには、必ずしも連続しているわけではない次のフェーズが含まれます(データの収集と処理、モデルの構築と利用、検証、展開、および運用と監視)。 AIシステム分類のための OECD フレームワークのディメンジョンは、AIシステムのライフサイクルの段階と関連付けて、説明責任に関連するAIアクターを特定できます。
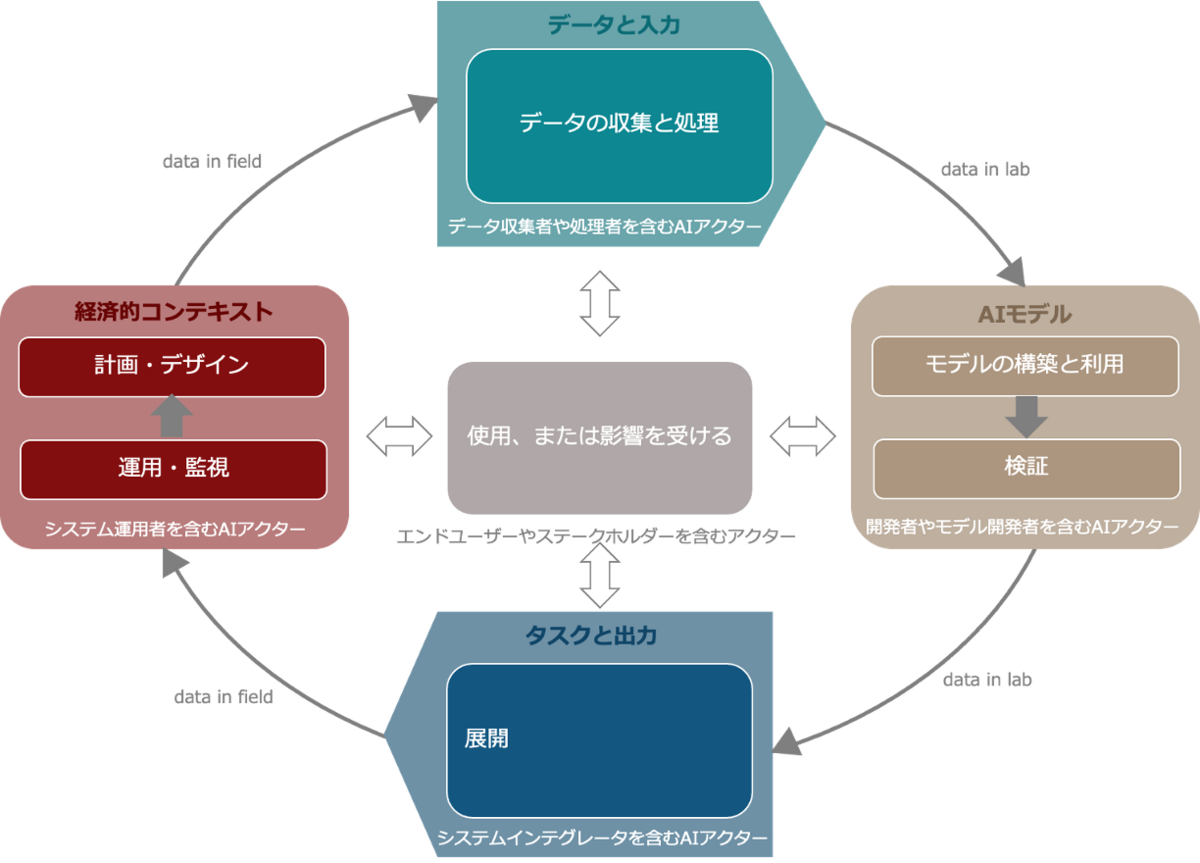
このフレームワークは、AIシステム開発の倫理的・社会的な側面を考慮した上で、その開発と利用を促進するための指針を提供します。フレームワークは定期的に見直し、必要に応じて更新していく必要があります。
- フレームワークの継続的な見直し
- 動的な性質や社会・技術・法的な発展を考慮し、フレームワークの継続的な関連性を定期的に見直す必要があります
- フレームワークの各要素は独立しているが、相互に影響を与え合います
- データ収集の目的は、後の利用目的と一致させる必要があります
- AIシステムの汎用性
- 汎用性とは、訓練を受けたタスク以外にも複数のタスクを実行できる能力を指します
- 単一の指標ではなく、複数の基準を組み合わせて客観的に評価します
- 詳細
- フレームワークは、AIシステム開発の指針としてだけでなく、その進化に伴うリスクを評価するためにも利用できます
- フレームワークの各要素は、独立しているように見えますが、実際には相互に影響を与え合っています。例えば、タスクと出力の定義は、データと入力、そしてAIモデルの設計に影響を与えます
- データは、特定の目的のために収集されたものである必要があります。収集段階で意図していなかった目的に使用すると、タスクの理想的な目的と、データに基づいて達成できる目的との間にズレが生じる可能性があります
- AIシステムの汎用性は、単一の指標で測定することはできません。複数の基準を組み合わせて評価する必要があります。これらの基準には、タスクの類似性、データの多様性、モデルの複雑性などが含まれます
以後原文の2章では各ディメンジョンを掘り下げて、詳細な説明が述べられていますが、ボリュームが多く内容が詳細であるため本まとめでは省略します。3章では具体的なAIシステムに対して本フレームワークを用いて整理された具体例が載っています。単純にフレームワークを説明するだけのものは多いと思いますが、実際にフレームワークを利用した実例が盛り込まれているのは非常に有益だと思います。次回のブログで生成AIアプリケーションについて実践してみたいと思います。
Next Step
4章のNext stepではAIシステムの開発と利用に伴うリスクを評価するための枠組みの構築について論じており、AIシステムの分類、インシデントの追跡、リスク評価のフレームワークの3つが論点となっています。
- AIシステムの分類では、実世界の事例をもとに分類基準を洗練していくことが提案されています。わかりやすい評価と正確な評価の間でトレードオフがあることも指摘されており、状況に応じて詳細な質問が必要になる場合もあるとしています
- AIインシデントの追跡では、共通の報告フレームワークを構築することが目指されています。これにより、世界的に一貫性のあるインシデント報告が可能となり、OECDのグローバルAIインシデント追跡システムへのデータ蓄積にも役立ちます
- リスク評価フレームワークの開発では、AIシステムの分類に加え、ガバナンスやリスク緩和プロセスなどの情報を用いて、倫理的・社会的なリスクを評価することができるようになるとしています。政策立案者や企業など様々な関係者が実務的に活用できることが期待されます
リスク評価の際に考慮すべき基準として、影響の深刻さ・範囲、利用者の選択可能性などが挙げられています。OECDは、国際的な相互運用性を促進するため、AIリスク評価・管理に取り組む様々なグループとの連携・調整を図ることも重要視しています。なお、AIリスクの議論は、機能安全やサイバーセキュリティなどの既存の評価フレームワークを補完するものであり、人権や責任ある企業行動に関するガイドラインとも密接に関連しているとされています。